
基于360容器云的K8s MCP Server
基于360容器云的K8s MCP Server
容器化时代

(1)物理机时代:多个应用程序会跑在一台机器上。
(2)虚拟机时代:一台物理机器安装多个虚拟机(VM),一个虚拟机跑多个程序。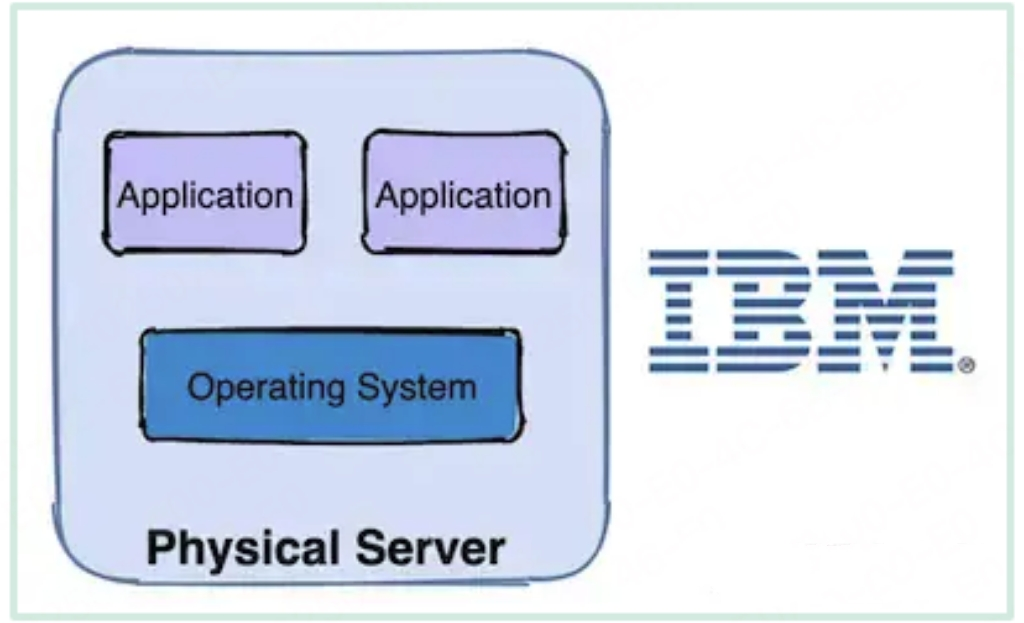
缺点:
- 资源占用多
- 冗余步骤多
- 启动速度慢
(3)容器化时代:一台物理机运行多个容器实例(container),一个容器跑一个或多个程序。
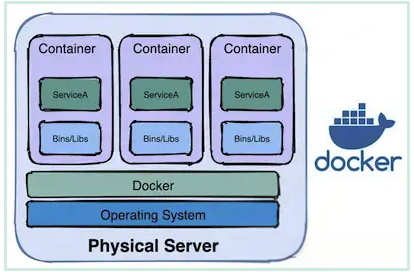
Linux容器:
由于虚拟机存在这些缺点,Linux发展出了另一种虚拟化技术:Linux容器(Linux Containers,缩写为LXC)。
Linux容器不是模拟一个完整的操作系统,而是对进程进行隔离。或者说,在正常进程的外面套了一个保护层。对于容器里面的进程来说,它接触到的各
种资源都是虚拟的,从而实现与底层系统的隔离。
特点:
- 启动快
- 资源占用少
- 体积小
Docker简介:
Docker的定义:
Docker属于Linux容器的一种封装,提供简单易用的容器使用接口。它是目前最流行的Linux容器解决方案。
Docker将应用程序与该程序的依赖,打包在一个文件里面。运行这个文件,就会生成一个虚拟容器。程序在这个虚拟容器里运行,就好像在真实的物理
机上运行一样。
Docker和KVM对比:
- 启动时间
Docker秒级启动
KVM分钟级启动 - 轻量级
容器镜像通常以M为单位,虚拟机以G为单位,容器资源占用小
容器共享宿主机内核,系统级虚拟化,占用资源少,容器性能基本接近物理机
虚拟机需要虚拟化一些设备,具有完整的OS,虚拟机开销大,因而降低性能,没有容器性能好 - 安全性
由于共享宿主机内核,只是进程隔离,因此隔离性和稳定性不如虚拟机,容器具有一定权限访问宿主机内核,存在安全隐患 - 使用要求
KVM基于硬件的完全虚拟化,需要硬件CPU虚拟化技术支持
容器共享宿主机内核,可运行在主机的Linux的发行版,不用考虑CPU是否支持虚拟化技术
Docker架构: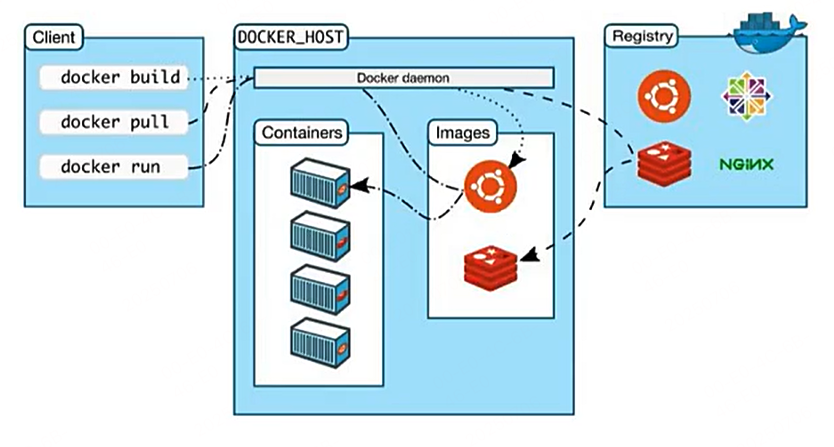
Docker daemon后端
Client客户端发送指令给Docker daemon来工作
Registry是镜像仓库
docker pull
docker pull 是指挥docker daemon从镜像仓库Registry中拉取需要的镜像,到本地的镜像仓库Images中
镜像可以理解为一个光盘,里面装了操作系统和软件
docker run
docker run 是命令docker daemon运行本地的镜像仓库Images中的镜像,生成容器Containers
镜像是一个类型(规范),容器是实例。
Images镜像仓库中,一种镜像只有一个,但是容器(实例)可以多个
docker run将一个死的操作系统启动起来,得到一个容器
容器中可以启动进程、服务之类的
docker build
命令docker daemon 利用Images本地镜像来创造一个新的镜像
相当于一个镜像最基本的就是有一个操作系统,然后可以基于这个来不断扩充,可以基于最原始的操作系统的镜像来扩充,也可以基于扩充之后的镜像再扩充
image镜像
Docker把应用程序及其依赖,打包在image文件中。只有通过这个文件,才能生成Docker容器
同一个image文件,可以生成多个同时运行的容器实例
镜像不是一个单一的文件,而是有多层
容器其实就是在镜像的最上面加了一层读写层,在运行容器里面做的任何文件改动,都会写到这个读写层里面。如果容器删除了,最上面的读写层也就删除了,改动也就丢失了
容器
docker run 命令会从image文件生成一个正在运行的容器实例
docker container run 命令具有自动抓取image文件的功能。如果发现本地没有指定的image文件,就会从仓库自动抓取
容器有的会自动终止,有的不会
image文件生成的容器实例,本身也是一个文件,称为容器文件
容器生成,就会同时存在两个文件:image文件和容器文件
关闭容器并不会删除容器文件,只是容器停止运行

以通俗的方式理解一个简易的 K8s 部署项目全流程
(一)前置理解:K8s 是什么?(类比生活场景)
K8s(Kubernetes)就像一个 “智能快递仓库管理员”:
- 仓库里有很多 “集装箱”(Pod),每个集装箱装着容器的实例(快递箱);
- 管理员能自动分配集装箱位置、管理数量(比如爆单时多开几个集装箱);
- 还有一本 “地址簿”(Service),记录每个集装箱的访问入口。
(二)部署流程 step by step(从项目到上线)
- 准备阶段:把项目打包成 “快递箱”(容器化)
为什么要容器化?
就像寄快递前要把物品装进标准箱子,容器化能让项目在任何环境中 “开箱即用”,避免 “在我电脑上能跑,上线就报错” 的问题。怎么做?
写一个《装箱指南》(Dockerfile),告诉电脑如何打包项目:
# 用Java项目举例
FROM openjdk:17-jdk-slim
COPY target/my-app.jar /app/ # 把打包好的jar包放进容器
CMD ["java", "-jar", "/app/my-app.jar"] # 告诉容器启动时运行这个命令
执行命令打包成 “快递箱”(镜像):
docker build -t my-project:v1 . # -t是命名镜像,:v1是版本号
- 搭建 “快递仓库”(准备 K8s 集群)
- 类比:仓库可以是自家小院(本地集群)或大型物流中心(云服务器)。
- 怎么做?
本地开发:可以用 Minikube 搭建单节点集群(像在自家小院搭临时仓库);
生产环境:用云服务商(如阿里云 ACK、AWS EKS)搭建多节点集群(大型物流中心,更可靠)。
- 给 “快递箱” 写 “入库单”(创建 K8s 配置文件)
- 类比:入库单要写清楚 “放多少个箱子”“放在哪里”“怎么访问”。
- 核心配置文件(YAML 格式):
Deployment 文件(管理快递箱数量):
apiVersion: apps/v1 # 指定使用的 Kubernetes API 版本,apps/v1 是 Deployment 资源的稳定版本
kind: Deployment # 指定资源类型为 Deployment,用于管理 Pod 副本集
metadata: # 资源的元数据
name: my-project-deployment # Deployment 的名称,用于标识和引用该资源
spec: # Deployment 的规格定义
replicas: 3 # 声明要运行的 Pod 副本数量,类似于准备3个相同的"快递箱"
selector: # 定义如何选择要管理的 Pod
matchLabels: # 通过标签匹配 Pod
app: my-project # 匹配具有 app=my-project 标签的 Pod
template: # Pod 模板,定义了创建 Pod 时使用的配置
metadata: # Pod 的元数据
labels: # Pod 的标签
app: my-project # 为 Pod 添加 app=my-project 标签,与 selector 匹配
spec: # Pod 的规格定义
containers: # 容器列表,每个 Pod 可以包含多个容器
- name: my-project-container # 容器名称
image: my-project:v1 # 使用的镜像,类似于从镜像仓库拉取的"快递箱"
ports: # 容器暴露的端口列表
- containerPort: 8080 # 容器内应用监听的端口号
Service 文件(给快递箱贴 “门牌号”):
apiVersion: v1 # 指定使用的 Kubernetes API 版本
kind: Service # 指定资源类型为 Service,用于暴露应用服务
metadata: # 资源的元数据
name: my-project-service # Service 的名称,用于标识和引用该资源
spec: # Service 的规格定义
type: NodePort # 服务类型为 NodePort,通过节点端口暴露服务给外部访问
selector: # 定义如何选择Pod
app: my-project # 匹配具有 app=my-project 标签的 Pod,关联到前面 Deployment 创建的 Pod
ports: # 端口映射配置
- port: 80 # Service 对外暴露的端口,外部客户端通过此端口访问服务
targetPort: 8080 # 映射到后端 Pod 容器的端口,需与容器内应用监听的端口一致(如 Deployment 中定义的 8080)
- 把 “快递箱” 搬进仓库(部署到 K8s)
- 类比:按入库单把快递箱放到指定位置,并告诉管理员管理规则。
- 怎么做?
先把镜像上传到 “快递中转站”(镜像仓库,如 Docker Hub、私有仓库):
docker login # 登录仓库
docker push my-project:v1 # 上传镜像
用 kubectl 命令 “提交入库单”:
kubectl apply -f deployment.yaml # 部署应用
kubectl apply -f service.yaml # 部署服务
查看部署状态(像查快递物流):
kubectl get pods # 查看Pod是否运行成功
kubectl get services # 查看服务地址
- 验收 “快递”(验证服务是否正常)
- 类比:打开快递箱,检查物品是否完好,地址是否正确。
- 怎么做?
找到服务的访问地址:
# 假设输出中NodePort是30080,集群节点IP是192.168.1.100
kubectl get services my-project-service
访问地址:http://192.168.1.100:30080,确认应用正常响应。
6. “仓库管理员” 的其他操作
- 快递爆单时(扩容):
kubectl scale deployment my-project-deployment --replicas=5 # 增加到5个Pod
- 更新快递箱内容(版本升级):
kubectl set image deployment/my-project-deployment my-project-container=my-project:v2 # 更换为v2版本镜像
- 出问题时回滚(退回旧快递):
kubectl rollout undo deployment/my-project-deployment # 回滚到上一个版本
(三)总结核心逻辑
容器化:把项目打包成标准镜像(快递箱),确保环境一致;
K8s 集群:提供自动化管理的 “仓库”,负责分配资源;
配置文件:用 YAML 告诉 K8s “要多少快递箱”“怎么访问”;
部署与验证:上传镜像、应用配置,最后检查服务是否可用。
(四)一些常见疑问以及注意点
(1)没有 k8s 可以使用 docker 吗?
在业务不太复杂的情况下是直接使用 Docker。尽管 k8s 有很多好处,但是它比较复杂,业务简单可以放弃使用 k8s, k8s 适合业务达到一定规模后启用。
(2)没有 Docker 可以使用 k8s 吗?
k8s 只是一个容器编排器,没有容器无法编排。
k8s 经常与 Docker 进行搭配使用,但是也可以使用其他容器,如 RunC、Containerted 等。
k8s集群架构:
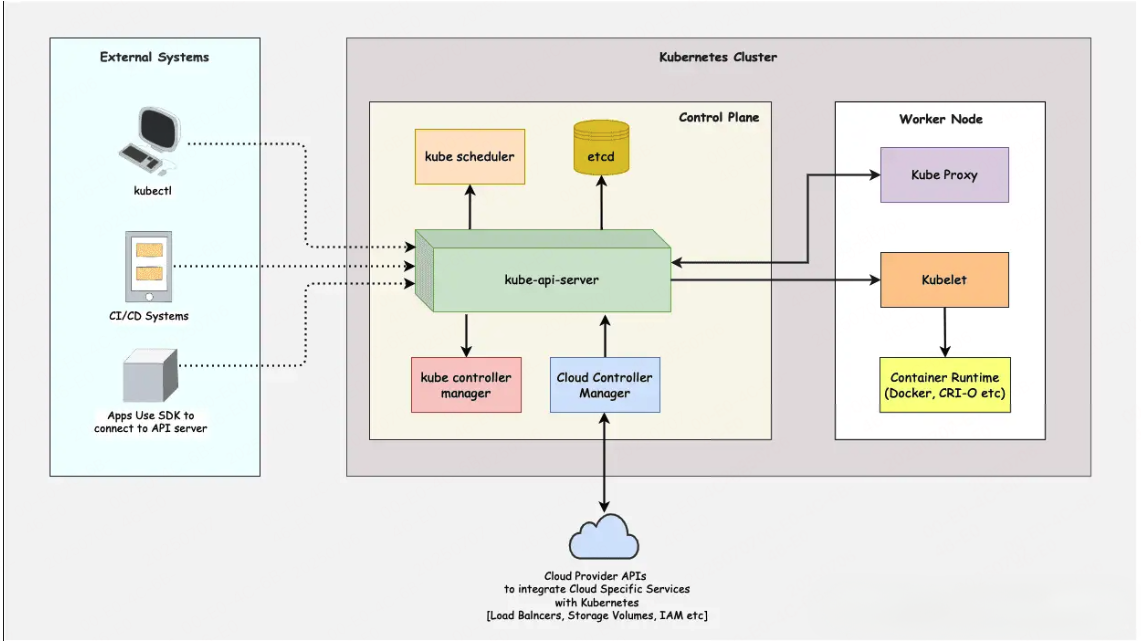
外部系统(External Systems)
kubectl:Kubernetes 的命令行工具,供用户与 Kubernetes API 服务器交互,完成资源的创建、删除、更新等操作。
CI/CD Systems: 持续集成/持续部署系统可以使用Kubernetes API来自动化应用的部署和管理。
Apps Use SDK to connect to API server: 应用程序可以使用SDK连接到Kubernetes API服务器,以实现更复杂的集成和自动化。
Kubernetes 集群(Kubernetes Cluster)
Kubernetes集群采用的是主从架构(Master-Slave Architecture) ,主要由两个角色组成:
控制平面(Control Plane) :负责集群的整体管理和调度。
工作节点(Worker Node) :负责实际运行应用容器。
控制平面是 Kubernetes 的“大脑”,主要负责接收用户指令、调度任务、监控运行状态。
控制平面的核心组件:

所有这些组件通常运行在 Master 节点上。在生产环境中,控制平面可以做高可用部署(即多个 Master 节点):
- 保证 apiserver 的可用性(通过负载均衡)
- 保证 etcd 的数据冗余与高一致性(通常部署 3 个及以上节点)
- 避免单点故障,增强容灾能力
工作节点(Worker Node)
每个 Node 是实际运行容器的机器(虚拟机或物理机)。
核心组件:
云提供商APIs
Kubernetes可以通过云提供商APIs与云服务进行集成,例如负载均衡器、存储卷和身份认证等。这使得Kubernetes能够利用云平台提供的各种服务来增强其功能。
工作流程
开发者通过 kubectl 提交 YAML 清单到 apiserver。
apiserver 验证请求,并将信息存储到 etcd。
scheduler 监听到新 Pod 创建请求,并根据调度算法分配到合适的 Node。
对应 Node 上的 kubelet 接收到任务,调用 Container Runtime 启动容器。
kube-proxy 设置好服务发现和访问规则,确保内部通信正常。
常用kind介绍
Pod:最小部署单元
Pod 是 K8s 中最小的可调度单元。一个 Pod 包含一个或多个 容器(通常是 Docker 容器) ,这些容器共享网络命名空间、存储卷和运行时环境。简单来说,Pod 就像一个 “逻辑主机”,里面的容器如同在同一台物理机上运行,拥有相同的网络 IP 和端口空间。
- 示例:一个 Web 应用的 Pod 可能包含两个容器 —— 一个运行 Web 服务的容器,另一个运行日志收集的容器(两者需共享日志文件存储)。
Pod 的核心特性
- 容器共享资源
- 网络:Pod 内所有容器共享一个 IP 地址和端口范围,容器间通过
localhost:端口直接通信;对外表现为一个独立的网络实体。 - 存储:Pod 可以定义共享存储卷(Volume),容器通过挂载卷实现数据共享或持久化(如共享配置文件、日志等)。
- 网络:Pod 内所有容器共享一个 IP 地址和端口范围,容器间通过
- 生命周期短暂
- Pod 是 “一次性” 的,一旦被创建,其生命周期不可修改(如不能直接修改容器镜像、增减容器)。若需更新,需
删除旧 Pod 并创建新 Pod。 - 当 Pod 所在节点故障时,K8s 会销毁该 Pod,并在其他节点重建(依赖控制器管理)。
- Pod 是 “一次性” 的,一旦被创建,其生命周期不可修改(如不能直接修改容器镜像、增减容器)。若需更新,需
- 自主管理与依赖控制器
- Pod(无控制器管理)不具备自愈能力,一旦故障会永久消失。
- 实际使用中,Pod 通常由控制器(如 Deployment、StatefulSet、DaemonSet)管理,控制器负责保证 Pod 的数量、状态和更新策略。
apiVersion: v1 # 指定使用的 Kubernetes API 版本
kind: Pod # 指定资源类型为 Pod,是 Kubernetes 中最小的可部署单元
metadata: # 资源的元数据
name: nginx-pod # Pod 的名称,用于标识和引用该资源
spec: # Pod 的规格定义
containers: # 容器列表,一个 Pod 可以包含多个紧密关联的容器
- name: nginx # 容器名称
image: nginx:1.24 # 使用的镜像,这里指定使用 Nginx 1.24 版本
ports: # 容器暴露的端口列表
- containerPort: 80 # 容器内应用监听的端口号,Nginx 默认监听 80 端口
这个配置文件定义了一个名为 nginx-pod 的 Pod,其中运行了一个基于 nginx:1.24 镜像的容器,并将容器内的 80 端口暴露出来。这个 Pod 没有指定任何持久化存储或高级调度策略,仅作为一个简单的 Nginx Web 服务器实例运行。在实际生产环境中,通常会使用 Deployment 或 ReplicaSet 来管理 Pod,而不是直接创建独立的 Pod。
Pod 的生命周期:
Pod 从创建到销毁会经历多个阶段,可通过kubectl describe pod <pod-name>查看Status.Phase:
- Pending:Pod 已被 K8s 接受,但容器尚未全部启动(如镜像拉取中、调度中)。
- Running:Pod 已绑定到节点,且至少一个容器处于运行状态(或初始化容器运行中)。
- Succeeded:所有容器正常退出(退出码为 0),且不会重启。
- Failed:所有容器已退出,且至少一个容器非 0 状态退出。
- Unknown:K8s 无法获取 Pod 状态(通常因节点通信故障)。
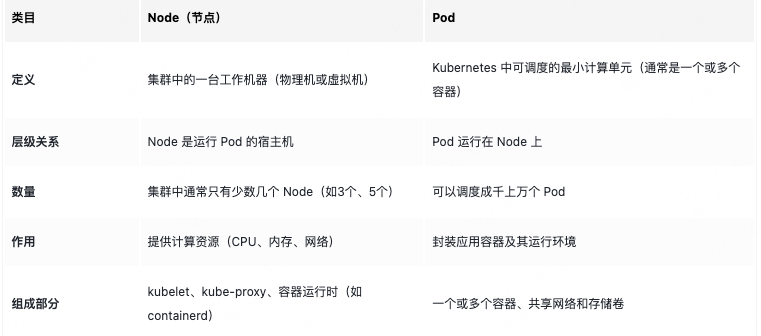
Node和Pod的对比:
Deployment:无状态应用的部署控制器
在 Kubernetes(k8s)中,Deployment 是一个核心的工作负载资源,用于声明式地管理 Pod 和 ReplicaSet,提供了 Pod 的创建、更新、回滚等全生命周期管理能力。它是日常使用中最常用的资源之一,尤其适合部署无状态应用。
什么是无状态?
“无状态” 用于描述应用程序的一种特性,Deployment 管理的无状态应用具备以下特点:
数据存储方面
- 不依赖本地存储:无状态应用不会将关键数据持久保存在运行它的 Pod 所在的节点上。例如,一个基于 Node.js 开发的简单 Web 服务,它处理用户请求并返回结果,不会在 Pod 所在的节点硬盘上保存用户数据、订单记录等关键信息。数据通常会被存储到独立的外部存储系统,像 MySQL 数据库、Redis 缓存等。这样做的好处是,当 Pod 因为节点故障、升级等原因被删除重建后,应用程序可以从外部存储重新获取数据,继续正常工作,而不会因为 Pod 的变动丢失数据。
- 无状态数据关联:各个实例(Pod)之间没有紧密的数据依赖关系。比如多个提供相同服务的 Web 应用 Pod,每个 Pod 都可以独立处理请求,不需要依赖其他 Pod 的数据来完成自身的业务逻辑。它们就像一个个独立的个体,彼此之间在数据层面互不干扰。
应用实例方面
- 可随意替换:无状态应用的 Pod 是完全等价的,它们的功能相同,对外部表现一致。所以在需要扩容、缩容,或者 Pod 出现故障需要重新创建时,新创建的 Pod 可以无缝替代原来的 Pod。例如,当网站访问量增加,需要增加 Web 服务器实例时,通过 Deployment 可以快速创建多个相同的 Pod,这些新的 Pod 能够像之前的 Pod 一样处理用户请求,用户不会察觉到 Pod 的变化。
- 无特定启动顺序:Pod 启动时,不需要依赖其他特定 Pod 先启动来获取配置信息或完成某些初始化操作。
Deployment对Pod的管理:
如果数量不足 replicas,则新建 Pod
如果数量过多,则删除多余的 Pod
如果标签相同但镜像等配置不同,则更新 Pod
Deployment 不直接控制 Pod,而是通过创建一个 ReplicaSet,再由 ReplicaSet 具体去创建 Pod,维护副本数量,做滚动更新。
ReplicaSet
Kubernetes 采用分层抽象来管理应用部署,核心层级关系如下:
Deployment(部署) → ReplicaSet(副本控制器) → Pod(容器组)
- 类比现实场景
- Deployment 类似 “项目总规划”,定义最终要达成的状态(如 3 个 Nginx 实例);
- ReplicaSet 类似 “施工队”,负责具体执行(创建 3 个 Pod,并确保数量始终达标);
- Pod 则是 “工人”,实际运行应用程序。
ReplicaSet 的核心职责:确保 Pod 副本数稳定
- 基本概念:
- ReplicaSet 是 Kubernetes 的资源对象,通过 标签选择器(Label Selector) 关联目标 Pod;
- 核心功能:监控并维持指定数量的 Pod 副本,若 Pod 意外删除或崩溃,会自动创建新实例。
- 关键参数示例:
apiVersion: apps/v1 # 指定使用的 Kubernetes API 版本
kind: ReplicaSet # 指定资源类型为 ReplicaSet,用于确保指定数量的 Pod 副本始终运行
metadata: # 资源的元数据
name: nginx-rs # ReplicaSet 的名称,用于标识和引用该资源
spec: # ReplicaSet 的规格定义
replicas: 3 # 指定期望的 Pod 副本数量,Kubernetes 将自动维持 3 个运行中的 Pod
selector: # 定义如何选择和管理 Pod
matchLabels: # 通过标签匹配 Pod
app: nginx # 匹配具有 app=nginx 标签的 Pod,控制已存在 Pod 的生命周期
template: # Pod 模板,定义新创建 Pod 的配置
metadata: # Pod 的元数据
labels: # Pod 的标签
app: nginx # 必须与 selector 中的标签匹配,确保 ReplicaSet 能管理这些 Pod
spec: # Pod 的规格定义
containers: # 容器列表,每个 Pod 可以包含多个容器
- name: nginx # 容器名称
image: nginx:1.23 # 使用的 Docker 镜像,指定 Nginx 1.23 版本
这个配置文件定义了一个名为 nginx-rs 的 ReplicaSet,它会确保集群中始终有 3 个运行 nginx:1.23 镜像的 Pod 副本。ReplicaSet 通过标签选择器 (app: nginx) 来管理这些 Pod,当 Pod 因任何原因终止时,会自动创建新的 Pod 来替换它们。
ReplicaSet vs Deployment
需要注意的是,虽然 ReplicaSet 可以直接管理 Pod 副本,但在实际生产环境中,更常用的是 Deployment。Deployment 是一个更高级的资源,它自动创建并管理 ReplicaSet,同时提供额外功能:
- 滚动更新:支持平滑升级应用版本(如从 Nginx 1.23 到 1.24)
- 回滚机制:出现问题时可快速回退到上一个稳定版本
- 暂停 / 恢复:支持暂停部署过程,进行中间状态检查
因此,除非有特殊需求(如需要自定义 ReplicaSet 的行为),否则建议优先使用 Deployment 来管理无状态应用。
为什么 Deployment 不直接管理 Pod?—— 分层设计的优势
解耦复杂功能,提升扩展性:
- Deployment 专注于 “部署策略”(如滚动更新、回滚);
- ReplicaSet 专注于 “副本控制”,两者职责分离,便于独立演进。
支持历史版本管理:
- 每次 Deployment 更新会创建新的 ReplicaSet,旧 ReplicaSet 保留用于回滚;
- 例如:从 Nginx 1.23 升级到 1.24 时,会生成
nginx-rs-v1和nginx-rs-v2,通过切换 ReplicaSet 实现版本回退。
兼容旧版本控制器(ReplicationController):
- ReplicaSet 是 ReplicationController 的升级版本,支持更灵活的标签选择器(如
matchExpressions); - Deployment 基于 ReplicaSet 构建,确保向后兼容。
matchExpressions:
apiVersion: apps/v1 kind: ReplicaSet metadata: name: example-rs spec: replicas: 3 selector: matchExpressions: - {key: "app", operator: "In", values: ["webapp", "backend"]} - {key: "tier", operator: "NotIn", values: ["db"]} template: metadata: labels: app: webapp tier: frontend spec: containers: - name: my-container image: my-image:latestmatchExpressions是标签选择器(Label Selector)的一种表达方式,用于更灵活、强大地筛选 Pod。相比于简单的matchLabels方式,matchExpressions可以通过逻辑运算符构建更复杂的筛选条件。matchExpressions的结构是一个数组,每个元素都是一个对象,包含以下字段:- key:标签的键,也就是标签定义中的名称部分 ,比如
app、tier等。 - operator:操作符,定义了如何匹配标签值。常见的操作符有:
- In:表示标签值在指定的列表中。例如
{"key": "env", "operator": "In", "values": ["dev", "test"]},会匹配标签env=dev或env=test的 Pod。 - NotIn:表示标签值不在指定的列表中。例如
{"key": "env", "operator": "NotIn", "values": ["prod"]},会匹配除了env=prod之外的所有 Pod。 - Exists:表示存在指定键的标签,不关心标签值是什么。比如
{"key": "app", "operator": "Exists"},会匹配所有带有app标签的 Pod。 - DoesNotExist:表示不存在指定键的标签。比如
{"key": "app", "operator": "DoesNotExist"},会匹配所有没有app标签的 Pod。
- In:表示标签值在指定的列表中。例如
- values:一个字符串数组,用于配合
In和NotIn操作符,指定匹配或排除的标签值列表。当操作符为Exists或DoesNotExist时,该字段为空 。
matchLabels则是一种简单的标签匹配方式,它要求 Pod 的标签必须和指定的标签完全匹配。例如matchLabels: {app: webapp},就只会匹配标签为app=webapp的 Pod,无法像matchExpressions那样构建复杂的逻辑条件 。Deployment 与 ReplicaSet 的协作流程:以滚动更新为例
初始状态:
- Deployment 创建 ReplicaSet
rs-v1,维持 3 个 Nginx:1.23 的 Pod。
- Deployment 创建 ReplicaSet
执行更新(修改 image 为 nginx:1.24):
- Deployment 会创建新的 ReplicaSet
rs-v2,并逐渐增加其副本数(如先创建 1 个新 Pod); - 同时减少
rs-v1的副本数(删除 1 个旧 Pod),确保总副本数不变(3 个)。
- Deployment 会创建新的 ReplicaSet
滚动过程示意:
阶段1:rs-v1=3 → rs-v2=0 阶段2:rs-v1=2 → rs-v2=1 阶段3:rs-v1=1 → rs-v2=2 阶段4:rs-v1=0 → rs-v2=3(更新完成)回滚机制:
- 若更新后应用异常,Deployment 可切换回旧 ReplicaSet
rs-v1,快速恢复到之前的版本。
- 若更新后应用异常,Deployment 可切换回旧 ReplicaSet
- ReplicaSet 是 ReplicationController 的升级版本,支持更灵活的标签选择器(如
Service:服务发现与负载均衡
在 Kubernetes 中,Service 是核心资源之一,用于解决 Pod 的动态性带来的网络访问问题。它为一组具有相同功能的 Pod 提供稳定的网络端点(IP 地址和端口),实现 Pod 的负载均衡和服务发现,是 K8s 中服务暴露和内部通信的关键组件。
apiVersion: v1 # 指定使用的 Kubernetes API 版本
kind: Service # 指定资源类型为 Service,用于暴露应用服务
metadata: # 资源的元数据
name: nginx-service # Service 的名称,用于标识和引用该资源
spec: # Service 的规格定义
selector: # 定义如何选择后端 Pod
app: nginx # 匹配具有 app=nginx 标签的 Pod,关联到前面 Deployment 创建的 Pod
ports: # 端口映射配置
- protocol: TCP # 指定协议类型为 TCP(默认值,可省略)
port: 80 # Service 对外暴露的端口,集群内部可通过此端口访问服务
targetPort: 80 # 映射到后端 Pod 容器的端口,需与容器内应用监听的端口一致
type: ClusterIP # Service 类型为 ClusterIP(默认值,可省略),仅在集群内部可访问
这个配置文件定义了一个名为 nginx-service 的 Service,它通过 app: nginx 标签选择器关联到之前 Deployment 创建的 Nginx Pod。Service 在集群内部创建了一个稳定的虚拟 IP(ClusterIP),将外部请求通过端口 80 转发到后端 Pod 的 80 端口。
说明:
- Service 与 Pod 的关联:
- Service 通过
selector字段匹配具有app: nginx标签的 Pod - 这些 Pod 由前面的 Deployment(如
my-nginx)创建和管理 - 当 Deployment 扩缩容或替换 Pod 时,Service 会自动更新其端点列表
- Service 通过
- 端口映射:
port: 集群内部访问 Service 的端口(例如:http://<ClusterIP>:80)targetPort: 后端 Pod 容器实际监听的端口(需与容器配置一致)- 如果
port和targetPort值相同,可以只写一个port字段简化配置
- ClusterIP 类型:
- 默认类型,仅在集群内部可访问
- 自动分配一个集群内部的虚拟 IP(ClusterIP)
- 通常用于内部微服务之间的通信,如前端服务访问后端 API
如何访问该 Service:
- 集群内部:可通过
http://nginx-service:80或http://<ClusterIP>:80访问 - 集群外部:无法直接访问,需要结合 Ingress 或将 Service 类型改为
NodePort/LoadBalancer
常见的type类型:
ClusterIP(默认):仅集群内部可访问,示例配置:
spec: type: ClusterIP # 可省略(默认) ports: - port: 80 targetPort: 80NodePort:在每个节点上开放一个端口(范围:30000-32767),外部可通过
任意节点IP:NodePort访问。例如:spec: type: NodePort ports: - port: 80 # Service内部端口 targetPort: 80 # Pod端口 nodePort: 30080 # 节点开放的端口(可选,不指定则自动分配)LoadBalancer:需云服务商支持,自动创建云负载均衡器,并将流量转发到 Service 的 NodePort。示例:
spec: type: LoadBalancer ports: - port: 80 targetPort: 80ExternalName:无需选择器,直接将 Service 映射到外部域名。例如:
spec: type: ExternalName externalName: example.com # 外部服务域名通过 K8s 的 DNS 插件(如 CoreDNS),集群内 Pod 访问
my-service.default.svc.cluster.local时,会被解析为example.com。Headless Service(无头服务):不分配 ClusterIP,通过 DNS 返回后端 Pod 的 IP 列表,适用于需要知道每个 Pod 具体地址的场景(如分布式数据库)。配置时需指定
clusterIP: None:spec: clusterIP: None # 无头服务标志 selector: app: mysql ports: - port: 3306 targetPort: 3306访问时,DNS 会返回所有匹配 Pod 的 IP(如
mysql-0.mysql-service.default.svc.cluster.local)。Headless Service 的特殊之处:
Headless Service 不分配 ClusterIP,而是通过 DNS 直接返回Pod 的稳定域名,而非单纯的 IP。这些域名格式固定,不受 Pod IP 变化影响。Headless Service 通常与StatefulSet配合使用,后者为每个 Pod 提供稳定的序号和域名。
Service如何做到的服务发现?
1. 第一步:给服务一个 “永久身份证”(Service 资源创建)
当你在 Kubernetes 中创建一个 Service,本质是做了两件事:
- 分配固定标识:Kubernetes 会给 Service 分配一个固定的 Cluster IP(集群内部 IP)和 DNS 域名(如
nginx-service.default.svc.cluster.local),这个地址不会随 Pod 变化而改变; - 定义 “找谁” 的规则:通过标签选择器(如
app=nginx)告诉 Service:“你要管理所有带这个标签的 Pod”。
2. 第二步:Pod 注册与监控
Kubernetes 的核心组件会自动做这件事:
- Pod 启动时:一旦 Pod 运行起来,Kubernetes 会自动将其 IP 地址和端口记录到对应 Service 的 “地址簿” 中(这个地址簿叫 Endpoints,存储了所有符合标签条件的 Pod 列表);
- Pod 变化时:当 Pod 因滚动更新被删除或新增时,Endpoints 会实时更新。
3. 第三步:流量路由机制
当客户端访问 Service 的固定 IP 或域名时,Kubernetes 会通过两种方式确保请求到达正确的 Pod:
- 内核级转发(Iptables/IPVS):Kubernetes 会在节点上设置网络规则,当流量到达 Service 的 Cluster IP 时,规则会自动将流量转发到 Endpoints 列表中的某个 Pod IP;
- DNS 解析:客户端也可以通过 Service 的域名访问(如
curl nginx-service),Kubernetes 的 DNS 组件会将域名解析为 Cluster IP,再通过上述转发机制找到 Pod。
为什么 Pod IP 会变?
- Pod 的设计哲学:Pod 是 “短暂的” 计算单元,可能因以下原因被删除重建:
- 滚动更新(Deployment 升级应用时,旧 Pod 被删除,新 Pod 生成新 IP);
- 节点故障(Pod 从故障节点迁移到新节点,IP 变化);
- 自动扩缩容(HPA 触发时,新增 Pod 的 IP 是动态分配的)。
- Service 的价值:正是因为 Pod IP 的 “不可靠”,才需要 Service 提供一个 “可靠” 的抽象层,这也是 Kubernetes 分层设计的核心优势之一。
Ingress
Ingress 是一种用于管理外部访问集群内服务的 API 对象,主要负责 HTTP/HTTPS 流量的路由、负载均衡、SSL 终止等功能。它相当于集群的 “入口网关”,简化了外部访问内部服务的配置。
在没有 Ingress 的情况下,集群外部访问服务只能通过:
- NodePort:每个 Service 暴露一个端口,访问地址为
NodeIP:Port。使用Ingress:简化端口管理,避免通过NodePort暴露大量端口(如 30000-32767),统一通过 80/443 端口接入。 - LoadBalancer:为每个服务申请一个云负载均衡器,成本高。
- Port-forward / kubectl proxy:临时调试用,不适合生产。
功能: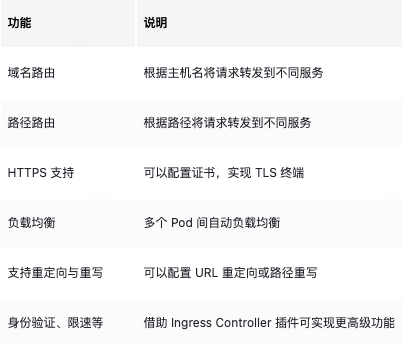
Ingress 的功能依赖两个部分:
- Ingress 资源:通过 YAML 定义的路由规则(如域名、路径、SSL 配置等)。
- Ingress 控制器:实际执行路由规则的组件(需单独部署,如 Nginx Ingress Controller、Traefik 等)。
注意:仅定义 Ingress 资源无法生效,必须部署对应的控制器,控制器会监听 Ingress 资源的变化并应用规则。
常见 Ingress Controller: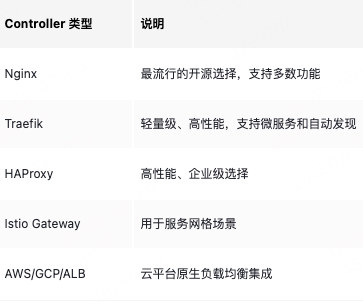
实际访问流程示例:
- 用户访问
http://example.com/web - 请求首先到达集群外部的负载均衡器(或直接到 Ingress Controller)
- Ingress Controller 根据
web-ingress规则,将请求转发到my-webService - Service 根据其
selector将请求转发到对应的 Pod(如 Nginx、Tomcat 等应用)
+--------------+
| Internet |
+------+-------+
|
+-------v--------+
| Ingress | ← 配置路由规则的资源
| (定义规则) |
+-------+--------+
|
+--------v---------+
| Ingress Controller| ← 实际负责转发流量
| (如 Nginx, Traefik)|
+--------+---------+
|
+-----v------+
| Kubernetes |
| Services |
+-----+------+
|
+--v--+
| Pod |
+-----+
apiVersion: networking.k8s.io/v1 # 指定使用的 Kubernetes API 版本,networking.k8s.io/v1 是 Ingress 资源的稳定版本
kind: Ingress # 指定资源类型为 Ingress,用于外部流量路由
metadata: # 资源的元数据
name: web-ingress # Ingress 的名称,用于标识和引用该资源
spec: # Ingress 的规格定义
rules: # 路由规则列表,可定义多条规则
- host: example.com # 匹配的域名,外部请求的 Host 头必须是此域名
http: # HTTP 路由规则
paths: # 路径匹配规则列表
- path: /web # 匹配的 URL 路径前缀
pathType: Prefix # 路径匹配类型为前缀匹配(匹配以 /web 开头的所有路径)
backend: # 匹配成功后转发的后端服务
service: # 指定目标 Service
name: my-web # 目标 Service 的名称
port: # 目标 Service 的端口
number: 80 # 端口号,对应 Service 配置中的 port 字段
ConfigMap 与 Secret
在 Kubernetes 中,ConfigMap 和 Secret 是用于配置管理的两种核心资源类型,它们用于将配置和敏感数据(如密码、API 密钥)与容器解耦,让你的应用部署更加灵活、安全。
PersistentVolumeClaim
PersistentVolumeClaim(PVC) 是一种资源对象,用于申请持久化存储空间(PersistentVolume,PV) 。它是 Pod 与底层存储之间的桥梁,用户通过 PVC 来请求磁盘,而不是直接绑定硬盘资源。
- PersistentVolume(PV) :由管理员创建或自动创建的存储资源,类似“硬盘”。
- PersistentVolumeClaim(PVC) :用户申请使用 PV 的方式,类似“租用硬盘”。
为什么需要 PVC?在容器运行时,容器内的数据是临时的(临时存储) ,容器重启或迁移后会丢失。如果需要保存数据库、文件上传等数据,就必须使用 PVC 来绑定到稳定的硬盘。
Namespace
Namespace(命名空间) 是一种用于对集群中的资源进行逻辑隔离和分组管理的机制。可以把它理解为集群中的「虚拟子集群」,用于将资源划分为多个相互独立的空间。并非所有的资源都可以用命名空间进行隔离。
基于360容器云OPEN API的k8s-mcp-server
tool:
deploy_latest_image- 部署指定应用的指定deployment名称的指定模板id的镜像版本,如果不指定模板id,则部署最新的镜像版本
运行逻辑:
分为8个步骤 。
- step1:检查部署
获取应用信息
{
"id": 3290,
"name": "qapm",
"namespace": "qdgc",
"kubeNamespace": "qdgc"
}
通过指定的deployment名检查部署是否存在
- step2:解析部署元信息metaData
{
"strategy": {
"type": "RollingUpdate", // 部署策略为滚动更新,支持平滑升级
"rollingUpdate": {
"maxUnavailable": "25%", // 滚动更新期间最多允许25%的副本不可用
"maxSurge": "25%" // 滚动更新期间最多允许超过期望副本数25%的额外副本
}
},
"inPlace": false, // 不使用原地更新,会创建新Pod替换旧Pod
"replicas": {
"pub-bjwdt": 1 // 在pub-bjwdt集群中部署1个副本
},
"logTopic": {
"pub-bjwdt": { // pub-bjwdt集群的日志配置
"name": "pub-bjwdt", // 日志主题名称
"host": "xxx" // 日志收集服务地址
}
},
"newMeta": false, // 不创建新的元数据
"clusters": {
"pub-bjwdt": { // 定义pub-bjwdt集群配置
"name": "pub-bjwdt", // 集群名称
"replica": 1, // 副本数量
"logTopic": { // 该集群的日志主题配置
"name": "k8s_deployment_qdgc_qapm-home",
"host": "xxx"
},
"hostGroup": "default" // 主机组设置为默认组
}
},
"idcs": [
{
"area": "北京", // 数据中心所在区域
"idcNames": [
"bjwdt" // 数据中心名称
],
"clusters": [
"pub-bjwdt" // 该数据中心包含的集群
],
"vpc": {} // VPC配置(此处为空)
}
],
"networkType": "classic" // 网络类型设置为经典网络
}
- step3:获取部署模板列表
根据部署id,获取模板列表,两个分支。
// 如果template_id不为空字符串,则使用template_id对应的模板
if (template_id) {
tplInfo = tplList.find((tpl) => String(tpl.id) === template_id);
logPro(`指定的模板id: ${template_id}`, {
folder: "step3:获取部署模板列表",
filename: "template_id.txt",
});
if (!tplInfo || !tplInfo.template) {
throw new McpError(
-32603, // 对应InternalError
"指定的部署模板id不存在",
);
}
} else {
// 最新的一个
tplInfo = tplList[0];
logPro(`未指定模板id,使用最新的模板${tplInfo.id}`, {
folder: "step3:获取部署模板列表",
filename: "template_id.txt",
});
if (!tplInfo || !tplInfo.template) {
throw new McpError(
-32603, // 对应InternalError
"部署模板信息不完整",
);
}
}
模板列表: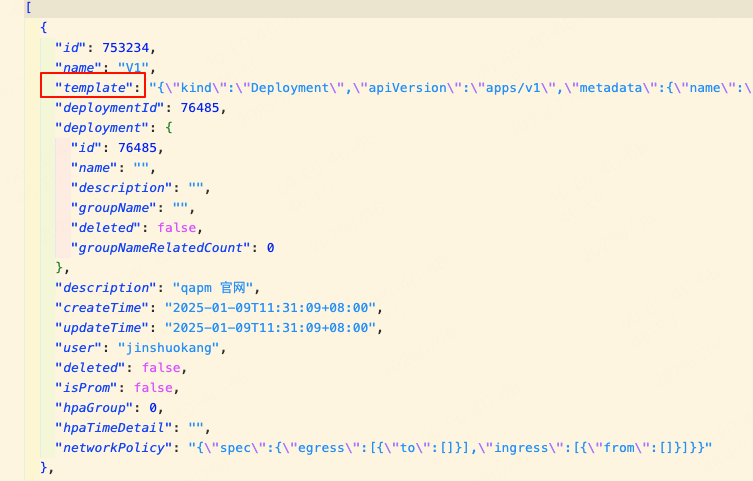
具体的template:
{
"kind": "Deployment", // 资源类型为Deployment,用于管理Pod副本集
"apiVersion": "apps/v1", // 使用apps/v1 API版本
"metadata": {
"name": "qapm-home", // Deployment名称
"creationTimestamp": null, // 创建时间戳(自动生成)
"labels": { // 标签,用于资源分类和选择
"app": "qapm-home", // 应用标识
"stark-app": "qapm", // Stark平台应用标识
"stark-ns": "qdgc" // Stark平台命名空间标识
}
},
"spec": {
"selector": { // 选择器,定义Deployment管理哪些Pod
"matchLabels": {
"app": "qapm-home", // 匹配具有该标签的Pod
"stark-res": "Deployment" // Stark平台资源类型标识
}
},
"template": { // Pod模板,定义Pod的规格
"metadata": {
"creationTimestamp": null,
"labels": { // Pod标签(必须包含selector中的标签)
"app": "qapm-home",
"stark-app": "qapm",
"stark-ns": "qdgc",
"stark-priority": "LS", // Stark平台优先级标识(低优先级)
"stark-res": "Deployment"
}
},
"spec": {
"containers": [ // 容器定义
{
"name": "qapm-home", // 容器名称
"image": "harbor.qihoo.net/qdgc-qapm/qapm-web:202407291835-ddc95a7", // 容器镜像(带版本哈希)
"resources": { // 资源请求与限制
"limits": { // 资源使用上限
"cpu": "1", // CPU上限1核
"ephemeral-storage": "30Gi", // 临时存储上限30GB
"memory": "2Gi" // 内存上限2GB
},
"requests": { // 资源请求(调度依据)
"cpu": "330m", // 请求0.33核CPU
"ephemeral-storage": "1Gi", // 请求1GB临时存储
"memory": "2Gi" // 请求2GB内存
}
},
"imagePullPolicy": "IfNotPresent", // 镜像拉取策略:本地不存在时拉取
"securityContext": {} // 安全上下文(未配置)
}
]
}
},
"strategy": {}, // 部署策略(为空,使用默认值)
},
"status": {} // 部署状态(自动生成)
}
- step4:构建镜像列表
// 构建镜像列表,转换成对象格式
const imageList = tplTemplate.spec.template.spec.containers.reduce(
(o: Record<string, string>, item: any) => {
if (item && typeof item === "object" && item.name && item.image) {
o[item.name] = item.image;
}
return o;
},
{},
);
{
"qapm-home": "harbor.qihoo.net/qdgc-qapm/qapm-web:202407291835-ddc95a7"
}
step5:升级部署

// 升级部署
const upgradeResult = await this.k8sService.upgradeDeployment(
existingDeployment.id,
tplInfo.id,
deploymentCluster,
imageList,
);
{
"templateIds": [
1343170
]
}
- step6:发布部署
// 发布部署 - 遍历所有集群进行发布
for (let i = 0; i < deploymentCluster.length; i++) {
const currentCluster = deploymentCluster[i];
// 检查集群配置是否存在
if (
!metaData.clusters[currentCluster] ||
typeof metaData.clusters[currentCluster] !== "object" ||
!("replica" in metaData.clusters[currentCluster])
) {
throw new McpError(
-32603, // 对应InternalError
`集群 ${currentCluster} 的配置信息不完整或无效`,
);
}
const replicas = (
metaData.clusters[currentCluster] as { replica: number }
).replica;
const publishResult = await this.k8sService.publishDeployment(
existingDeployment.id,
upgradeResult.templateIds[0],
currentCluster,
replicas,
);
if (!publishResult) {
throw new McpError(
-32603, // 对应InternalError
`在集群 ${currentCluster} 发布部署失败`,
);
}
}
- step7:监控Pod状态
let pods: PodInfo[] = [];
let allPodsReady = false;
for (let i = 0; i < 20; i++) {
// 等待5秒
await new Promise((resolve) => setTimeout(resolve, 5000));
const deploymentStatus = await this.k8sService.getDeploymentStatus(
existingDeployment.id,
deploymentCluster.join(","),
);
logPro(deploymentStatus, {
filename: "deploymentStatus.json",
folder: "step7:监控Pod状态",
});
if (
!deploymentStatus ||
!Array.isArray(deploymentStatus) ||
!deploymentStatus.length
) {
console.log("未获取到部署状态信息,继续等待...");
continue;
}
// 安全地提取所有Pod信息
pods = deploymentStatus.flatMap((status) =>
status && status.pods && Array.isArray(status.pods)
? status.pods
: [],
);
if (pods.length === 0) {
console.log("未找到Pod信息,继续等待...");
continue;
}
// 检查所有Pod是否已经启动完成
if (pods.every((pod) => pod && pod.state === "Running")) {
allPodsReady = true;
break;
}
console.log(
`当前 Pod 状态: ${pods
.map((pod) =>
pod
? `${pod.name || "未命名"}: ${pod.state || "未知"}`
: "未知Pod",
)
.join(", ")}`,
);
}
if (
!allPodsReady &&
pods.some((pod) => pod && pod.state !== "Running")
) {
const abnormalPods = pods.filter(
(pod) => pod && pod.state !== "Running",
);
throw new McpError(
-32603, // 对应InternalError
`有 ${abnormalPods.length} 台 Pod 启动异常,请到容器云查看详情`,
);
}
mcp Server json
{
"mcpServers": {
"k8s-mcp-server": {
"command": "npx",
"args": ["-y", "@q/k8s-mcp-server"],
"env": {
"K8S_KEY_ID": "xxx(必填)",
"K8S_SECRET_KEY": "xxx(必填)",
"K8S_APP_ID": "应用id(必填)",
"K8S_ENV": "prod",
"K8S_API_URL": "https://k8s.qihoo.net",
"K8S_DEPLOY_NAME": "deployment名(必填)",
"K8S_TEMPLATE_ID": "模板id(默认取第一个模板)",
"K8S_REGISTRY_URL": "harbor.qihoo.net"
}
}
}
}
Window system:
{
"mcpServers": {
"k8s-mcp-server": {
"command": "cmd",
"args": ["/c", "npx", "-y", "@q/k8s-mcp-server"],
"env": {
"K8S_KEY_ID": "xxx(必填)",
"K8S_SECRET_KEY": "xxx(必填)",
"K8S_APP_ID": "应用id(必填)",
"K8S_ENV": "prod",
"K8S_API_URL": "https://k8s.qihoo.net",
"K8S_DEPLOY_NAME": "deployment名(必填)",
"K8S_TEMPLATE_ID": "模板id(默认取第一个模板)",
"K8S_REGISTRY_URL": "harbor.qihoo.net"
}
}
}
}
MCP Inspector调试示例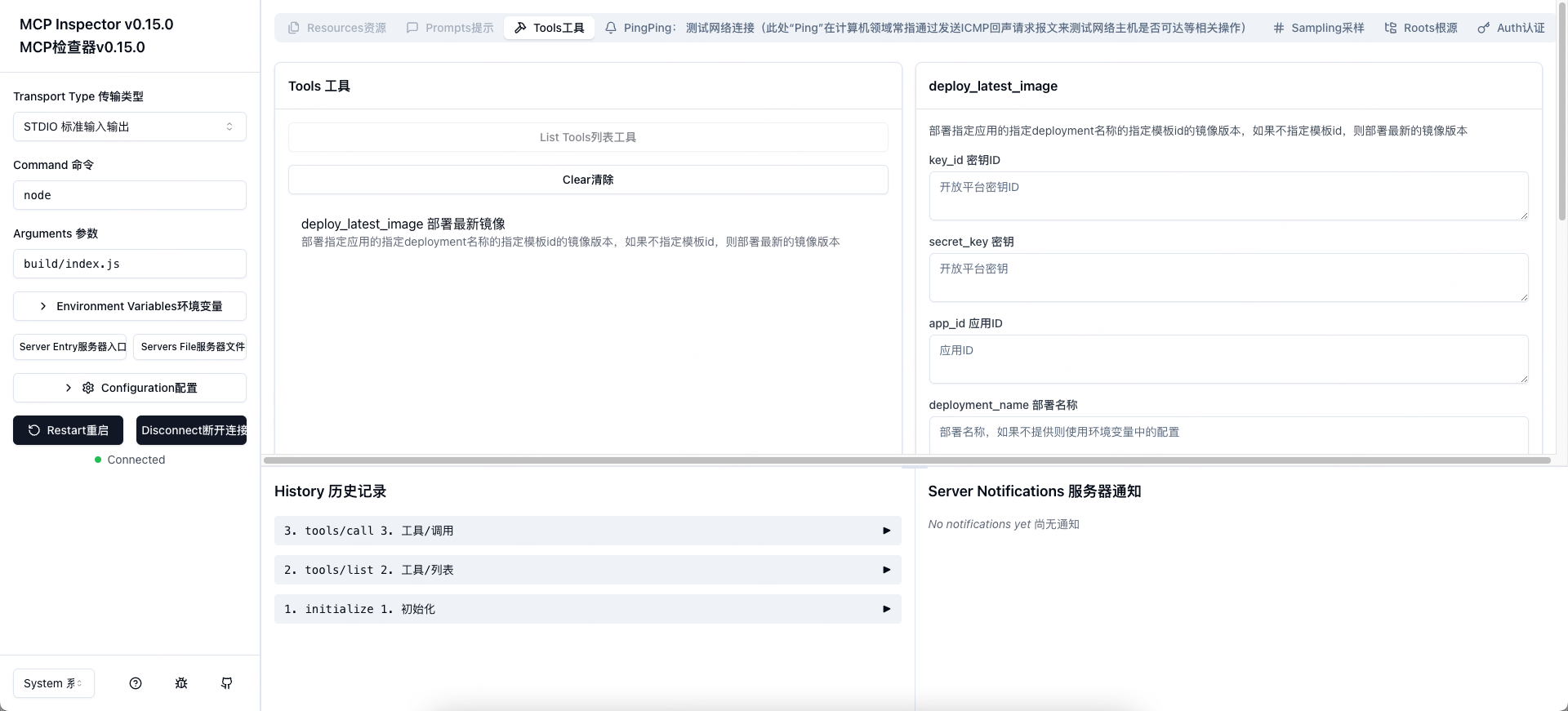
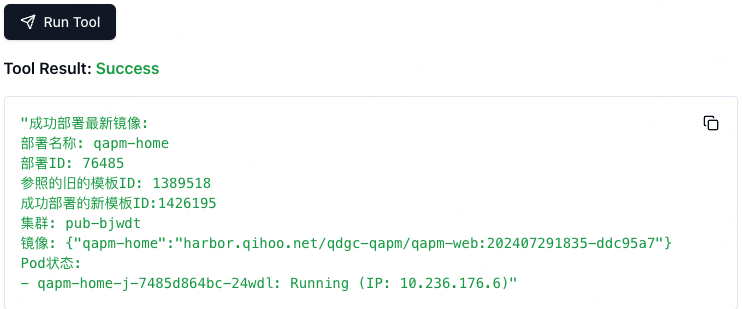
如何申请APIKeys(K8S_KEY_ID,K8S_SECRET_KEY)?
1.登录容器云https://k8s.qihoo.net/
2.项目管理=>应用概览
3.进入平台管理,点击APIKeys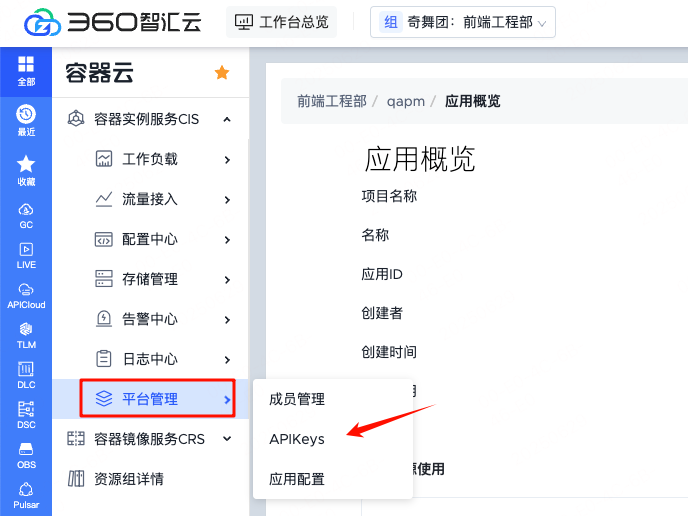
4.创建APIKey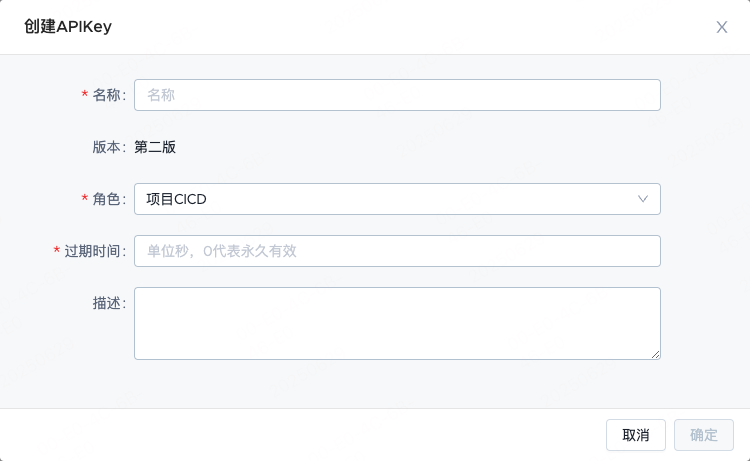
其他env参数:
1.K8S_APP_ID-应用id: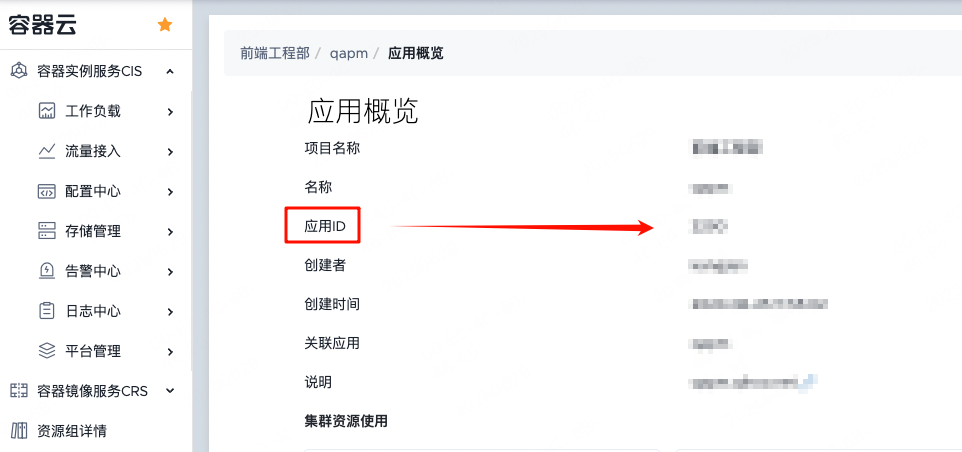
2.K8S_DEPLOY_NAME-deployment名:
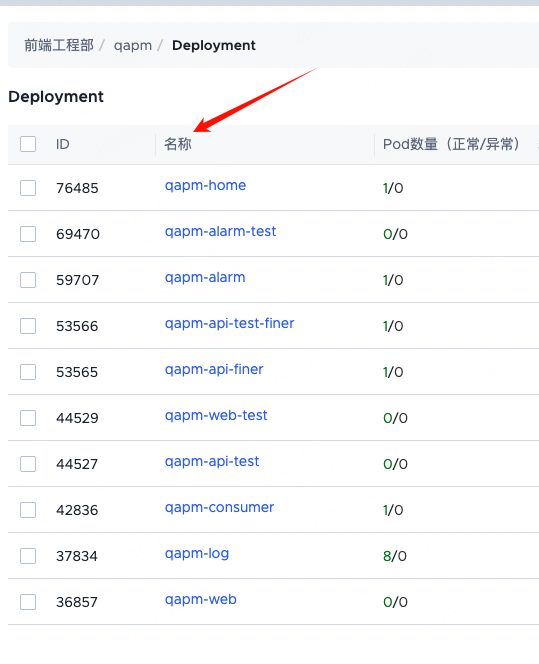
3.K8S_TEMPLATE_ID-模板id:
选择进入一个deployment,对应的就是模板列表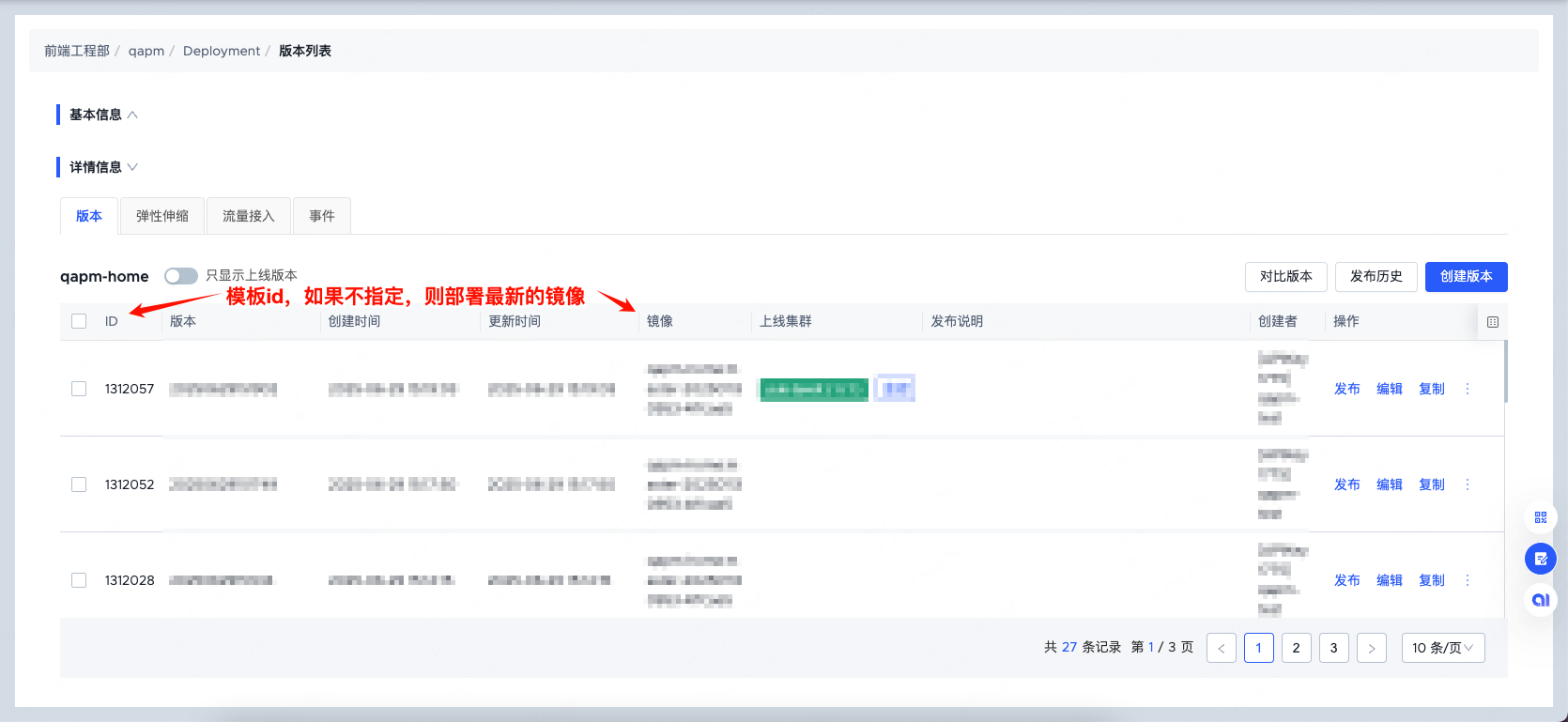
参考:
https://juejin.cn/post/7015729458959089701?searchId=2025070614342819DDBC0E977A9ED47412
https://juejin.cn/post/7499317287725940787